XPath 란 무엇입니까?
XPath는 XSLT 표준의 주요 요소입니다.
XPath는 XML 문서의 요소와 속성을 탐색하는 데 사용할 수 있습니다.
 | - XPath는 XML 경로 언어
- XPath는 "path like"구문을 사용하여 XML 문서의 노드를 식별하고 탐색합니다.
- XPath에는 200 가지가 넘는 내장 함수가 포함되어 있습니다.
- XPath는 XSLT 표준의 주요 요소입니다.
- XPath는 W3C 권장 사항입니다.
|
XPath 경로 표현식
XPath는 경로 표현식을 사용하여 XML 문서에서 노드 또는 노드 집합을 선택합니다.
이러한 경로 표현식은 기존의 컴퓨터 파일 시스템에서 사용하는 경로 표현식과 매우 유사합니다.
XPath 표준 함수
XPath는 200 가지가 넘는 내장 함수를 포함합니다.
문자열 값, 숫자 값, 부울 값, 날짜 및 시간 비교, 노드 조작, 시퀀스 조작 등의 기능이 있습니다.
오늘날 XPath 표현식은 JavaScript, Java, XML 스키마, PHP, Python, C 및 C ++ 및 기타 많은 언어에서도 사용할 수 있습니다.
XPath는 XSLT에서 사용됩니다.
XPath는 XSLT 표준의 주요 요소입니다.
XPath 지식을 사용하면 XSLT 지식을 최대한 활용할 수 있습니다.
XPath는 W3C 권장 사항입니다.
XPath 1.0은 1999 년 11 월 16 일에 W3C 권장 사항이되었습니다.
XPath 2.0은 2007 년 1 월 23 일에 W3C 권장 사항이되었습니다.
XPath 3.0은 2014 년 4 월 8 일에 W3C 권장 사항이되었습니다.
XPath 용어
노드
XPath에는 요소, 속성, 텍스트, 네임 스페이스, 처리 명령, 주석 및 문서 노드 등 7 가지 노드가 있습니다.
XML 문서는 노드 트리로 취급됩니다. 트리의 최상위 요소를 루트 요소라고합니다.
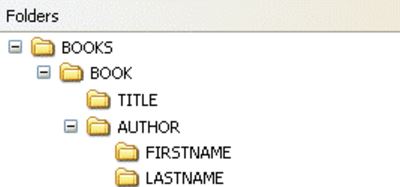
다음 XML 문서를 살펴보십시오.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
위 XML 문서의 노드 예 :
<bookstore> (root element node)
<author>J K. Rowling</author> (element node)
lang="en" (attribute node)
원자 값
원자 값은 자식 또는 부모가없는 노드입니다.
원자 값의 예 :
항목
항목은 원자 값 또는 노드입니다.
노드의 관계
부모의
각 요소 W 속성에는 하나의 상위가 있습니다.
다음 예제에서; book 요소는 제목, 저자, 연도 및 가격의 상위 항목입니다.
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
어린이
요소 노드는 0 개, 하나 이상의 자식을 가질 수 있습니다.
다음 예제에서; 제목, 저자, 연도 및 가격 요소는 모두 book 요소의 하위 요소입니다.
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
동기
부모가 같은 노드.
다음 예제에서; 제목, 저자, 연도 및 가격 요소는 모두 형제입니다.
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
선조
노드의 부모, 부모의 부모 등
다음 예제에서; title 요소의 조상은 book 요소와 bookstore 요소입니다.
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
자손
노드의 자식, 자식의 자식 등
다음 예제에서; 서점 요소의 자손은 책, 제목, 저자, 연도 및 가격 요소입니다.
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
XPath는 경로 표현식을 사용하여 XML 문서에서 노드 또는 노드 집합을 선택합니다. 경로 또는 단계를 따라 노드가 선택됩니다.
XML 예제 문서
아래 예제에서 다음 XML 문서를 사용합니다.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
노드 선택
XPath는 경로 표현식을 사용하여 XML 문서의 노드를 선택합니다. 경로 또는 단계를 따라 노드가 선택됩니다. 가장 유용한 경로 표현식은 다음과 같습니다.
| Expression | Description |
|---|
| nodename | Selects all nodes with the name "nodename" |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection no matter where they are |
| . | Selects the current node |
| .. | Selects the parent of the current node |
| @ | Selects attributes |
아래 표에서 몇 가지 경로 표현식과 표현식 결과를 나열했습니다.
| Path Expression | Result |
|---|
| bookstore | Selects all nodes with the name "bookstore" |
| /bookstore | Selects the root element bookstore Note: If the path starts with a slash ( / ) it always represents an absolute path to an element! |
| bookstore/book | Selects all book elements that are children of bookstore |
| //book | Selects all book elements no matter where they are in the document |
| bookstore//book | Selects all book elements that are descendant of the bookstore element, no matter where they are under the bookstore element |
| //@lang | Selects all attributes that are named lang |
조건부
술어는 특정 노드 또는 특정 값을 포함하는 노드를 찾는 데 사용됩니다.
술어는 대괄호 안에 항상 포함됩니다.
아래 테이블에서 조건문과 표현식의 결과가있는 경로 표현식을 나열했습니다.
| Path Expression | Result |
|---|
| /bookstore/book[1] | Selects the first book element that is the child of the bookstore element. Note: In IE 5,6,7,8,9 first node is[0], but according to W3C, it is [1]. To solve this problem in IE, set the SelectionLanguage to XPath: In JavaScript: xml.setProperty("SelectionLanguage","XPath"); |
| /bookstore/book[last()] | Selects the last book element that is the child of the bookstore element |
| /bookstore/book[last()-1] | Selects the last but one book element that is the child of the bookstore element |
| /bookstore/book[position()<3] | Selects the first two book elements that are children of the bookstore element |
| //title[@lang] | Selects all the title elements that have an attribute named lang |
| //title[@lang='en'] | Selects all the title elements that have a "lang" attribute with a value of "en" |
| /bookstore/book[price>35.00] | Selects all the book elements of the bookstore element that have a price element with a value greater than 35.00 |
| /bookstore/book[price>35.00]/title | Selects all the title elements of the book elements of the bookstore element that have a price element with a value greater than 35.00 |
알 수없는 노드 선택
XPath 와일드 카드를 사용하여 알 수없는 XML 노드를 선택할 수 있습니다.
| Wildcard | Description |
|---|
| * | Matches any element node |
| @* | Matches any attribute node |
| node() | Matches any node of any kind |
아래 표에서 몇 가지 경로 표현식과 표현식 결과를 나열했습니다.
| Path Expression | Result |
|---|
| /bookstore/* | Selects all the child element nodes of the bookstore element |
| //* | Selects all elements in the document |
| //title[@*] | Selects all title elements which have at least one attribute of any kind |
여러 경로 선택
| 연산자를 사용하면 여러 경로를 선택할 수 있습니다.
아래 표에서 몇 가지 경로 표현식과 표현식 결과를 나열했습니다.
| Path Expression | Result |
|---|
| //book/title | //book/price | Selects all the title AND price elements of all book elements |
| //title | //price | Selects all the title AND price elements in the document |
| /bookstore/book/title | //price | Selects all the title elements of the book element of the bookstore element AND all the price elements in the document
|
XML 예제 문서
아래 예제에서 다음 XML 문서를 사용합니다.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
XPath 축
축은 컨텍스트 (현재) 노드와의 관계를 나타내며 트리에서 해당 노드를 기준으로 노드를 찾는 데 사용됩니다.
| AxisName | Result |
|---|
| ancestor | Selects all ancestors (parent, grandparent, etc.) of the current node |
| ancestor-or-self | Selects all ancestors (parent, grandparent, etc.) of the current node and the current node itself |
| attribute | Selects all attributes of the current node |
| child | Selects all children of the current node |
| descendant | Selects all descendants (children, grandchildren, etc.) of the current node |
| descendant-or-self | Selects all descendants (children, grandchildren, etc.) of the current node and the current node itself |
| following | Selects everything in the document after the closing tag of the current node |
| following-sibling | Selects all siblings after the current node |
| namespace | Selects all namespace nodes of the current node |
| parent | Selects the parent of the current node |
| preceding | Selects all nodes that appear before the current node in the document, except ancestors, attribute nodes and namespace nodes |
| preceding-sibling | Selects all siblings before the current node |
| self | Selects the current node |
위치 경로 표현식
위치 경로는 절대 또는 상대 경로 일 수 있습니다.
절대 위치 경로는 슬래시 (/)로 시작하며 상대 경로는 그렇지 않습니다. 두 경우 모두 위치 경로는 하나 이상의 단계로 구성되며 각 단계는 슬래시로 구분됩니다.
An absolute location path:
/step/step/...
A relative location path:
step/step/...
각 단계는 현재 노드 집합의 노드에 대해 평가됩니다.
단계는 다음과 같이 구성됩니다.
- 축 (선택된 노드와 현재 노드 사이의 트리 관계 정의)
- 노드 테스트 (축 내의 노드 식별)
- 0 개 이상의 술어 (선택된 노드 집합을 더 구체화하기 위해)
위치 단계 구문은 다음과 같습니다.
axisname::nodetest[predicate]
예제들
| Example | Result |
|---|
| child::book | Selects all book nodes that are children of the current node |
| attribute::lang | Selects the lang attribute of the current node |
| child::* | Selects all element children of the current node |
| attribute::* | Selects all attributes of the current node |
| child::text() | Selects all text node children of the current node |
| child::node() | Selects all children of the current node |
| descendant::book | Selects all book descendants of the current node |
| ancestor::book | Selects all book ancestors of the current node |
| ancestor-or-self::book | Selects all book ancestors of the current node - and the current as well if it is a book node |
| child::*/child::price | Selects all price grandchildren of the current node |
XPath 표현식은 노드 집합, 문자열, 부울 또는 숫자를 반환합니다.
XPath 연산자
아래는 XPath 표현식에서 사용할 수있는 연산자 목록입니다.
| Operator | Description | Example |
|---|
| | | Computes two node-sets | //book | //cd |
| + | Addition | 6 + 4 |
| - | Subtraction | 6 - 4 |
| * | Multiplication | 6 * 4 |
| div | Division | 8 div 4 |
| = | Equal | price=9.80 |
| != | Not equal | price!=9.80 |
| < | Less than | price<9.80 |
| <= | Less than or equal to | price<=9.80 |
| > | Greater than | price>9.80 |
| >= | Greater than or equal to | price>=9.80 |
| or | or | price=9.80 or price=9.70 |
| and | and | price>9.00 and price<9.90 |
| mod | Modulus (division remainder) | 5 mod 2
|
몇 가지 예를 살펴봄으로써 기본 XPath 구문을 배우려고합니다.
XML 예제 문서
아래 예제에서 다음 XML 문서를 사용합니다.
"books.xml":
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
브라우저에서 "books.xml"파일을보십시오 .
XML 문서로드
XMLHttpRequest 객체를 사용하여 XML 문서를로드하면 모든 최신 브라우저에서 지원됩니다.
var xmlhttp = new XMLHttpRequest();
오래된 브라우저 (IE5와 IE6)에 대한 코드는 AJAX 튜토리얼에서 찾을 수 있습니다.
노드 선택
불행히도 다른 브라우저에서 XPath를 처리하는 방법은 다양합니다.
Chrome, Firefox, Edge, Opera 및 Safari는 evaluate () 메소드를 사용하여 노드를 선택합니다.
xmlDoc.evaluate(xpath, xmlDoc, null, XPathResult.ANY_TYPE,null);
Internet Explorer는 selectNodes () 메서드를 사용하여 노드를 선택합니다.
xmlDoc.selectNodes(xpath);
예제에서는 대부분의 주요 브라우저에서 사용할 수있는 코드를 포함 시켰습니다.
모든 제목 선택
다음 예제에서는 모든 제목 노드를 선택합니다.
첫 번째 책의 제목 선택
다음 예제에서는 bookstore 요소 아래에 첫 번째 책 노드의 제목을 선택합니다.
모든 가격 선택
다음 예제는 모든 가격 노드에서 텍스트를 선택합니다.
예
/bookstore/book/price[text()]
직접 해보기»
가격이 35보다 큰 가격 노드를 선택하십시오.
다음 예제는 가격이 35보다 높은 모든 가격 노드를 선택합니다.
예
/bookstore/book[price>35]/price
직접 해보기»
가격이 35보다 큰 제목 노드를 선택하십시오.
다음 예제는 가격이 35보다 높은 모든 제목 노드를 선택합니다.
예
/bookstore/book[price>35]/title
출처 : https://www.w3schools.com